
Democratize GenAI through Private AI
January 19, 2025
AI-powered Security Assistant For Fortinet
January 19, 2025Creating a Chatbot using Precision and NVIDIA AI Workbench
Revolutionize business information retrieval with a custom RAG chatbot powered by NVIDIA AI Workbench. Experience innovative AI-driven solutions for seamless data access.
+
Build Your Own Chatbot: Easy AI Information Retrieval
Searching for critical information across various company systems can be a universally frustrating experience. Whether you're in sales, HR, or customer support, locating the exact data you need often takes more time and effort than it should. Now, imagine a solution where you can simply ask a question and receive the correct answer within seconds. This is precisely what a Retrieval-Augmented Generation (RAG) chatbot offers—it quickly retrieves the most relevant details from your company’s documents.
Even better, creating such a powerful tool doesn’t require extensive infrastructure. With platforms like NVIDIA AI Workbench, you can build a RAG chatbot right on your personal computer. In this article, we’ll guide you through setting up your own RAG chatbot using an example project in the AI Workbench. You'll see how this advanced technology makes data retrieval easier and how it can be scaled to meet broader business needs.
Why Build a RAG Chatbot?
A RAG chatbot integrates natural language generation with the capability to search through internal data sources. Unlike traditional chatbots that depend only on pre-trained models, RAG retrieves real-time data before crafting its responses, ensuring both accuracy and contextual relevance in the answers.
This technology is well-suited for a variety of business applications, such as:
- HR departments answering policy questions quickly.
- Customer service teams instantly retrieving product details or FAQs.
- Sales teams accessing real-time data to improve response times during negotiations.
Getting Started: What You’ll Need
- NVIDIA AI Workbench is a versatile platform designed to run AI models seamlessly on any NVIDIA RTX GPU, whether locally or remotely. You can download it directly to get started.
- AI Workbench Hybrid RAG Project provides a customizable example that allows you to create your own chatbot. You can access the project and adapt it according to your requirements.
- To build a functional chatbot, you'll need to upload relevant internal documents, knowledge bases, or other data sources that the bot can use to retrieve information.
- For optimal performance, it's recommended to use a high-performance workstation PC equipped with an NVIDIA RTX GPU, preferably a Precision workstation featuring the NVIDIA RTX Ada Generation GPU, which ensures faster and more efficient processing.
Step-by-Step Guide to Building Your RAG Chatbot
To kick off your own RAG chatbot locally, you can follow these steps:
-
- Set up your NVIDIA NGC account and get your NVCF API key.
- Install NVIDIA AI Workbench and add the API Key Secret.
- Run the RAG Client.
- Pick a model, pick an inference mode, and add your data!
- Set up your NVIDIA NGC account and get your NVCF API key
- Navigate to the NVIDIA NGC sign-in pageand input an email to create your account:
- After setting up your account with your personal details, generate a run key:
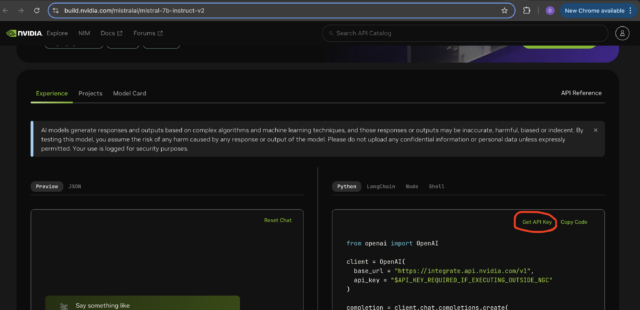
Save the generated key somewhere secure for later steps.
- Install NVIDIA AI Workbench and Add the API Key Secret
- Install NVIDIA AI Workbench:
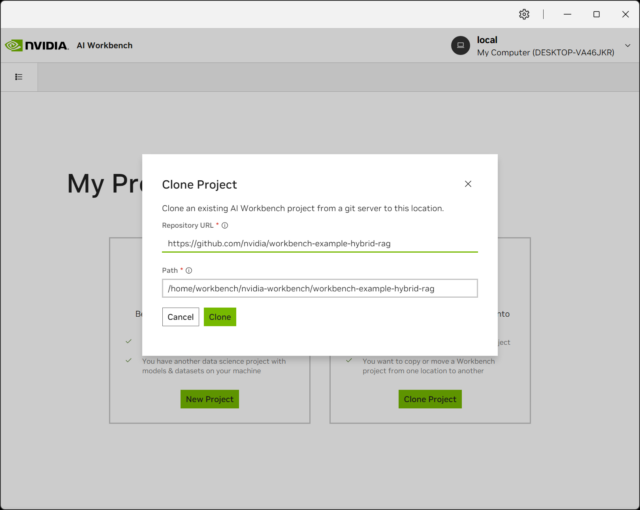
- Clone the AI Workbench Hybrid RAG project from GitHub:
- After the project completes building, this modal should pop up. You can input the key we generated earlier here:
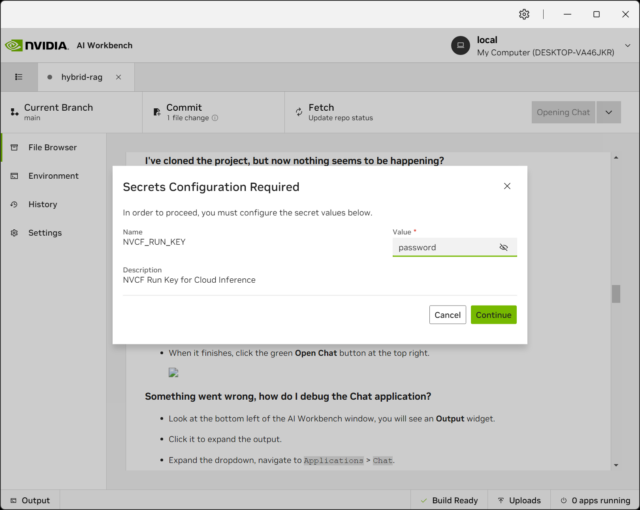
- If the modal does not pop up, you can input the API key by going to Environment→Secrets:
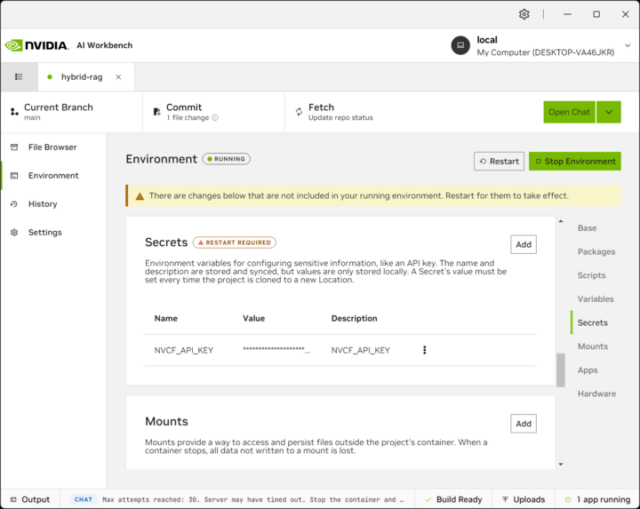
- Run the RAG Client
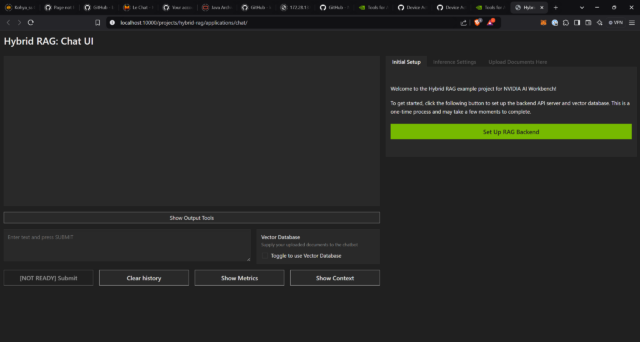
- Now, when you press “Open Chat,” this window to a chat interface should pop up:
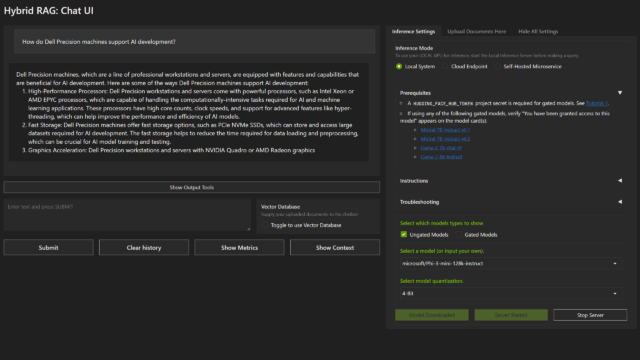
- Pick a model, pick an inference mode, and add your data
- Select “Local System” as the inference mode. This helps ensure that your data, queries, and computations remain completely private and self-contained on your local system.
- Then, select a model family.
- In our case, we used an Ungated Model, the Microsoft/Phi-3-mini-128-instruct with 4-Bit quantization:
Now that you’ve set up your chatbot, you can add data and start making queries. Make sure to test the chatbot by asking real questions based on the data you provided, which you know the exact answer to.
This step can be expanded as your company’s data needs grow. Regularly updating the chatbot with new information ensures it remains relevant and useful.
How Do We Scale This? Dell’s Validated Designs
Scaling an AI solution like a RAG chatbot can feel daunting, especially as your business grows and your chatbot needs to handle more queries, data, and complex tasks. Dell DVDs are designed to simplify this process by providing a roadmap for scalability, performance optimization and security. Dell developed this free design guide so that you are set up to succeed in creating a secure, performant and scalable AI solution.
Here are some of the basic principles you will learn by reading the guide:
Modular and Scalable Architecture
When you’re starting out with your RAG chatbot, it may handle only a few queries at a time. But as usage increases, so will the demands on your infrastructure. Dell’s validated architecture lays out a modular approach that allows your system to grow without needing major reconfigurations.
- Start small, scale as needed: Initially, deploy your chatbot on a personal PC or small server. As the number of users and queries grows, you can expand the system incrementally by adding resources.
- Kubernetes for dynamic scaling: Use Kubernetes so your chatbot infrastructure can automatically scale to accommodate increased demand. Resources are then allocated efficiently as your system grows.
On-Premises Data Security
As your RAG chatbot grows, so does the importance of securing your private data. Dell’s architecture emphasizes on-premises deployment for businesses that need to keep sensitive data in-house, away from cloud-based systems.
- Run your chatbot on local hardware: Dell’s architecture supports on-premises deployment, meaning you can grow your system on Dell PowerEdge servers or other local infrastructure, keeping your data protected.
- Faster response times: By keeping your data and processing local, you can expect faster responses as the system grows.
Performance Optimization with NVIDIA RTX Professional GPUs
Dell recommends leveraging NVIDIA RTX GPUs so that your chatbot scales efficiently while maintaining high performance.
- Incorporate NVIDIA RTX GPUs: Scaling with NVIDIA RTX GPUs ensures your chatbot can handle more data-intensive queries without suffering from slowdowns or latency issues. Depending on the models selected and you want to run it locally, you will want a 12GB or higher NVIDIA RTX GPU. Although, you don’t need to run it locally you can also run Workbench with NIMs or NeMO.
- Optimize for heavier workloads: When scaling up your workload, you also want to consider the hardware supporting it. Dell has options that can be scaled up to your workload:
-
-
- Tower Servers: Good for small to medium businesses needing a cost-effective, easy-to-manage solution. Perfect for starting small without the need for a full data center.
- Rack Servers: Better for larger-scale operations with existing IT infrastructure (e.g. a server room).
- AI Servers: Heavier duty— designed for intensive AI workloads, like deep learning and large-scale data processing.
- Edge Servers: Great for environments where data needs to be processed in real-time at remote locations. Useful for low-latency, distributed systems like IoT.
-
Why RAG and Scaling Matter for Your Business
A RAG chatbot simplifies how your business accesses critical information. Whether in HR, sales, or customer service, a RAG chatbot ensures that the right data is always at your fingertips, instantly pulling relevant information from your internal systems. This reduces time spent searching for answers, improves decision-making, and enhances overall productivity.
However, building the chatbot is just the start. As your business grows, your chatbot needs to scale alongside it. That’s where Dell’s validated AI design principles come in. Dell offers a proven framework for expanding your chatbot efficiently and securely, with modular architecture that allows you to grow seamlessly, on-premises deployment to protect sensitive data, and NVIDIA RTX GPUs to maintain high performance even under heavier workloads.
By implementing these scalable strategies, your RAG chatbot will evolve from a simple information retrieval tool into a powerful AI system that grows with your company—delivering fast, accurate insights every step of the way.